无需标注数据 云从科技及联合研究团队提出一种视觉模型自监督学习方法
游戏《光环》中的
人工智能科塔娜说过一句话,
“我是他的盾牌,我是他的利刃;我深知他,连同他的过去和未来”。
作为“六感”之首的视觉,占据了人类吸收外部信息的70%以上。如果说人工智能的远景是打造一个具有大脑、神经、躯干与四肢的机器人,那么,硬件基础是躯干、四肢,更重要的是,要使得机器人能看会想,能听会说,就要搭建神经和大脑。
训练视觉模型的目标是教会AI看见和理解现实世界,其中,点云视频理解对于智能体与世界的交互至关重要。
近日,国际计算机视觉顶会CVPR 2023在加拿大温哥华举行。作为国际计算机视觉与模式识别领域的三大顶级会议之一,CVPR备受关注。云从科技及联合研究团队的论文《PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos》(基于掩码预测的点云视频自监督学习)成功入选。

01
简介
从静态点云中解析现实世界已经取得了巨大的成就。最近,对点云视频的理解也越来越受关注。与此同时,自监督学习可以从未标注的数据中提取高质量的表征,这将为标注成本高昂的点云视频理解任务带来帮助。
因此,我们探索了以自监督的方式从点云视频中学习表征的方法。尽管基于对比学习和掩码预测的自监督学习范式已经在图像和静态点云领域显示出了强大的有效性,但是将这些方法直接扩展到点云视频上仍存在诸多挑战。
在本文中,我们提出了PointCMP,一种用于点云视频自监督学习的对比掩码预测框架。PointCMP采用双分支结构,同步学习点云视频的局部和全局时空信息。在此之上,我们提出了一个基于互相似度的增强模块,以实现基于特征的样本生成。
通过计算各局部表征与该样本全局语义之间的相似度,我们可以找到那些与语义高度相关的关键部分。将这些关键部分掩蔽可以提升自监督预测任务的挑战性,以促使模型学习更有效的表征。与此同时,我们也尝试擦除关键的特征通道,从而针对性的生成难负例用于全局对比学习。
02
方法
我们的PointCMP架构如图1所示。给定一个点云视频,首先将其均匀地分成多个视频片段。然后,将这些片段送入编码器得到局部Token以及具有全局语义的全局Token。接下来,将它们传递给基于互相似度的增强模块。
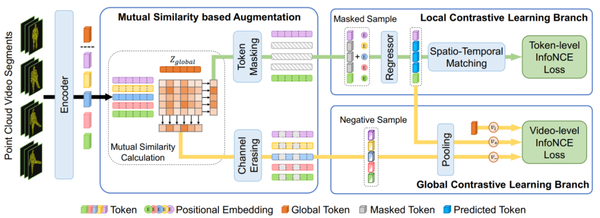
图1 PointCMP的架构示意图
从直觉上来说,当与全局Token具有较高相似度的局部Token可见时,预测任务会变得更容易。因此,我们掩蔽掉这些具有高相似度的局部Token以生成有难度的掩码样本。我们选择相似度高的Token作为关键Token。各局部Token所覆盖的点云通常有重叠,而视频片段之间有一定的信息隔离。
因此,我们选择包含最多个关键Token的视频片段,并将此片段下聚合而成的所有局部Token都掩蔽掉。此外,我们将具有高相关度的特征通道视为主通道,并将它们擦除以生成难负样本。直观上来说,擦除掉这些重要的主成分特征后势必会与原始样本形成一个负样本对。
我们将带有掩码的Token序列与位置编码相加后输给一个回归器,来预测被掩码处的表征。被预测的表征与编码器得到的相对应的原始表征组成正样本对,而与其余的组成负样本对。我们使用InfoNCE损失来完成此局部对比学习分支。
与此同时,我们还为样本的全局表征构建了全局对比学习分支。由回归器重新补全的Token序列经过池化层得到新的全局表征,并与原始全局表征构成正样本对。
擦除主特征通道后的Token序列经过池化层得到全局难负例。并且,同一批次内的其他视频的全局表征也作为当前样本的负样本。我们同样使用InfoNCE损失来完成此全局对比学习分支。
03
实验
首先,我们对预训练后的编码器进行微调,来评估PointCMP学习到的表征。我们将MSRAction-3D数据集同时用于预训练和端到端微调。当使用PSTNet作为编码器时,相对于基线,PointCMP预训练带来了显著的精度改进。
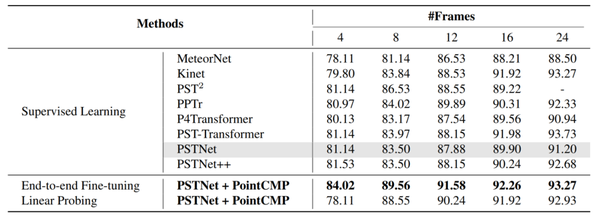
表1 MSRAction-3D数据集上的验证结果
如表1所示,在使用8 帧时,行为识别的精度从83.50%提高到89.56%。这表明,PointCMP预训练可以以自监督的方式从点云视频中学习到有益的知识,这有助于在微调后获得更高的精度。
然后,我们通过线性实验来验证PointCMP预训练所学到的表征的有效性。同样的,MSRAction-3D数据集被用于预训练和线性测试。预训练的编码器被冻结,并添加一个额外的线性分类器用于监督训练。我们的方法在大多数帧数设置下都超过了基线。这证明了PointCMP预训练让模型学习到了高质量的表征。

表2 NTU-RGBD (Cross-Subject) 数据集上的验证结果
此外,我们还在NTU-RGBD数据集上做了半监督实验,即在自监督预训练后用一部分有标注的数据微调模型。从表2的结果来看,当我们使用PSTNet作为编码器时,只用50%的标注数据微调模型就可以接近全监督的基线精度。这表明PointCMP预训练可以在无标注数据中挖掘数据自身所蕴含的知识,这不仅可以节约人力成本还可以将预训练模型作为初始化从而进一步提升模型的性能。

图2 高相似度局部Token及其邻域点(绿色)的可视化结果
我们在图2中进一步可视化了与全局Token具有高度相似性的关键局部Token及其邻域点。正如我们所看到的,与运动的关键身体部位相对应的点被突出显示。这与我们的直觉是一致的。通过掩蔽这些关键区域,鼓励编码器利用更多上下文进行掩码预测,以此学习更高质量的表征。
总结展望
自监督学习的优势主要是利用辅助任务从无标注数据中挖掘自身的监督信息。相比于利用特定任务的标注作为监督信息训练,这不仅可以节省标注成本,还可以使模型学习到更泛化的知识和对多种下游任务有价值的表征。在数据为王的时代,此特点也使得大家充分相信自监督学习才是人工智能的发展方向。
另一方面,点云视频含有丰富的动态视觉信息,可以帮助智能体充分了解这个实时变化的3D世界。且相比于传统视频以纹理信息为主,点云视频涵盖更精确的几何信息和位置坐标。
所以,点云视频可以为低能见度环境中的动作识别等任务提供保障。由此可见,点云视频理解对于人工智能系统与世界交互非常重要。在海量数据之上,借助自监督技术推动点云视频理解,也许会帮助我们打造一个能想会说、能听会看的AI。
您可能感兴趣
-
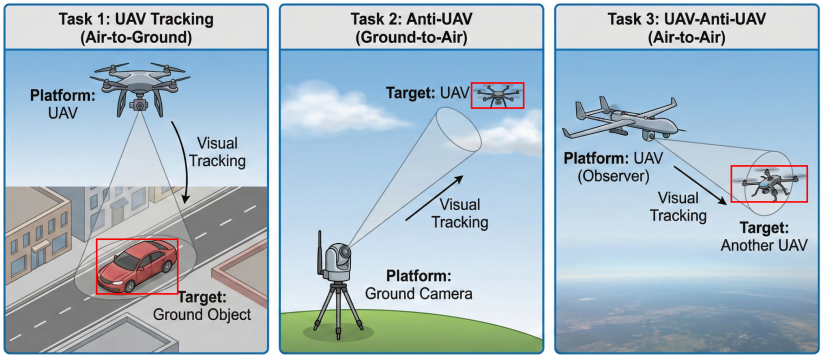 2025-12-12
2025-12-12当追踪者和目标都在低空高速飞行,传统的视觉追踪算法还能跟得住吗? 近日,来自云从科技、上海交通大学、香港科技大学(广州)、中山大学、中国科学院信息工程研究所的联合研究团队发布了一项硬核工作——UAV-Anti-UAV。这是业界首个针对“空对空”(Air-to-Air)场景的百万级多模态反无人机视觉追踪基准,并提出了基于Mamba的强力基线MambaSTS。MambaSTS在UAV-Anti-UAV基准的全部5个指标上均取得最佳的性能,这是云从科技在多模态大模型方面的又一次技术突破。面对双重动态干扰,现有的SOTA表现如何?让我们一探究竟!
-
-
 2023-07-19
2023-07-19云从科技在视觉大模型上取得重要进展,行人基础大模型在PA-100K、RAP V2、PETA、HICO-DET四个数据集上从阿里巴巴、日立等多家知名高校、企业与研究机构脱颖而出,刷新了世界纪录。







